AI factories reduce model deployment time
AI Factories Unleashed: Building Enterprise Infrastructure for Rapid Model Deployment in 2026

Last updated: February 23, 2026
Enterprise organizations are racing to build internal AI factories—integrated platforms that combine data pipelines, reusable algorithms, and automated deployment systems to accelerate AI development without requiring massive GPU investments. AI Factories Unleashed: Building Enterprise Infrastructure for Rapid Model Deployment in 2026 represents a fundamental shift from one-off AI projects to industrialized production systems that deliver models to production in weeks instead of months. Companies that master this approach gain competitive advantages through faster innovation cycles, lower development costs, and the ability to scale AI across their entire organization.
Key Takeaways
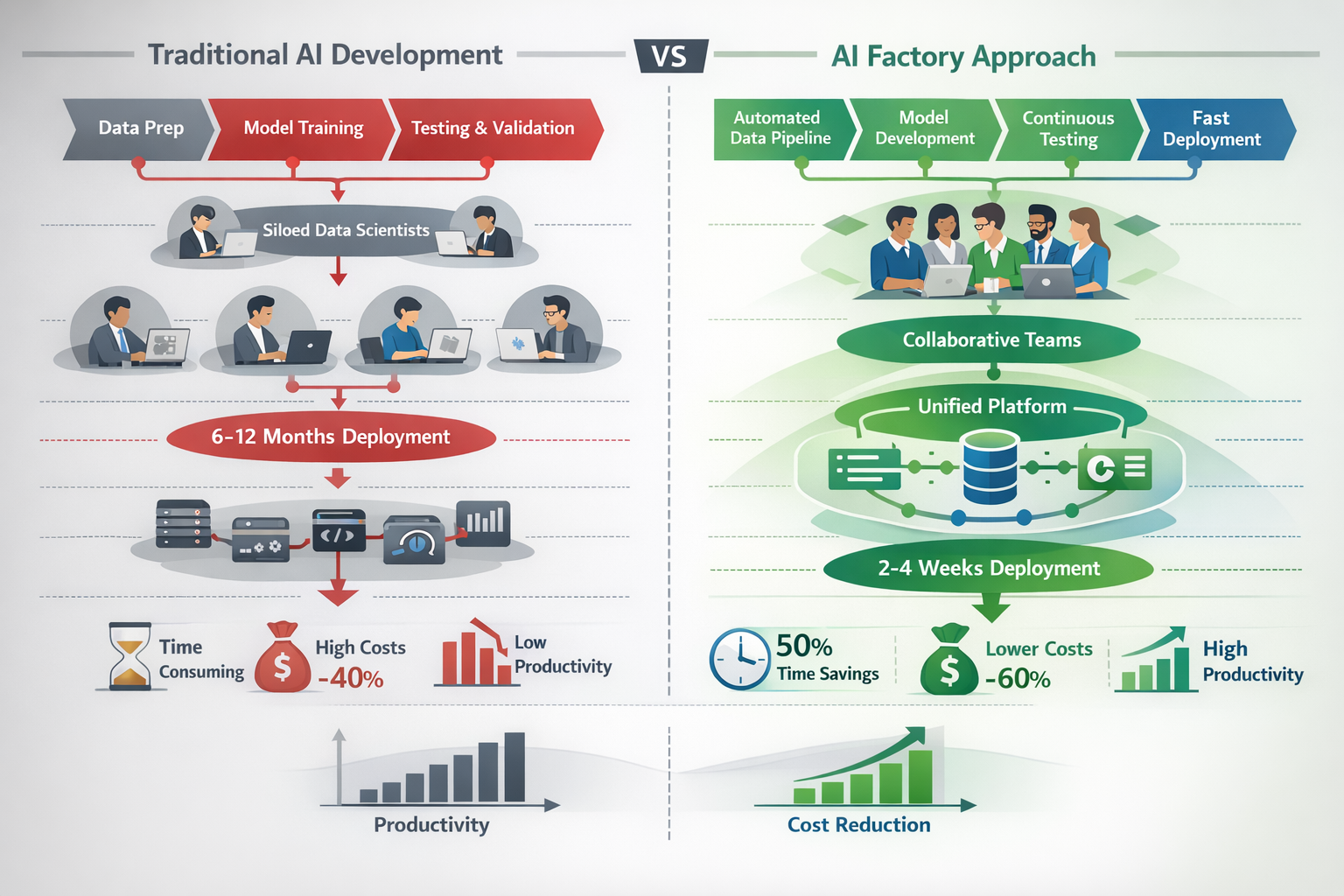
- AI factories reduce model deployment time from 6-12 months to 2-4 weeks by standardizing infrastructure, automating pipelines, and creating reusable components
- Agentic AI is expected to represent 10-15% of IT spending in 2026, but 70-80% of prior initiatives failed to scale due to infrastructure gaps
- Building an AI factory requires five core components: data infrastructure, model development platforms, orchestration systems, deployment automation, and monitoring tools
- Companies can start without massive GPU investments by leveraging cloud resources, optimizing existing infrastructure, and focusing on software-defined platforms
- European enterprises have established 13 AI factories across 17 member states, with AI server spending forecasted at $47 billion in 2026
- Power constraints are the primary bottleneck, with global data center electricity consumption projected to double between 2022 and 2026
- Successful AI factories prioritize repeatable processes over rushed deployments, with emphasis on bare metal automation and solid operational foundations
- NVIDIA's full-stack approach includes compute, networking, orchestration software, and digital twin design to prevent costly downtime in large-scale deployments
- Organizations must address cultural and organizational challenges alongside technical infrastructure to achieve meaningful returns
- Starting small with pilot projects and scaling gradually produces better outcomes than attempting enterprise-wide transformations immediately
Quick Answer
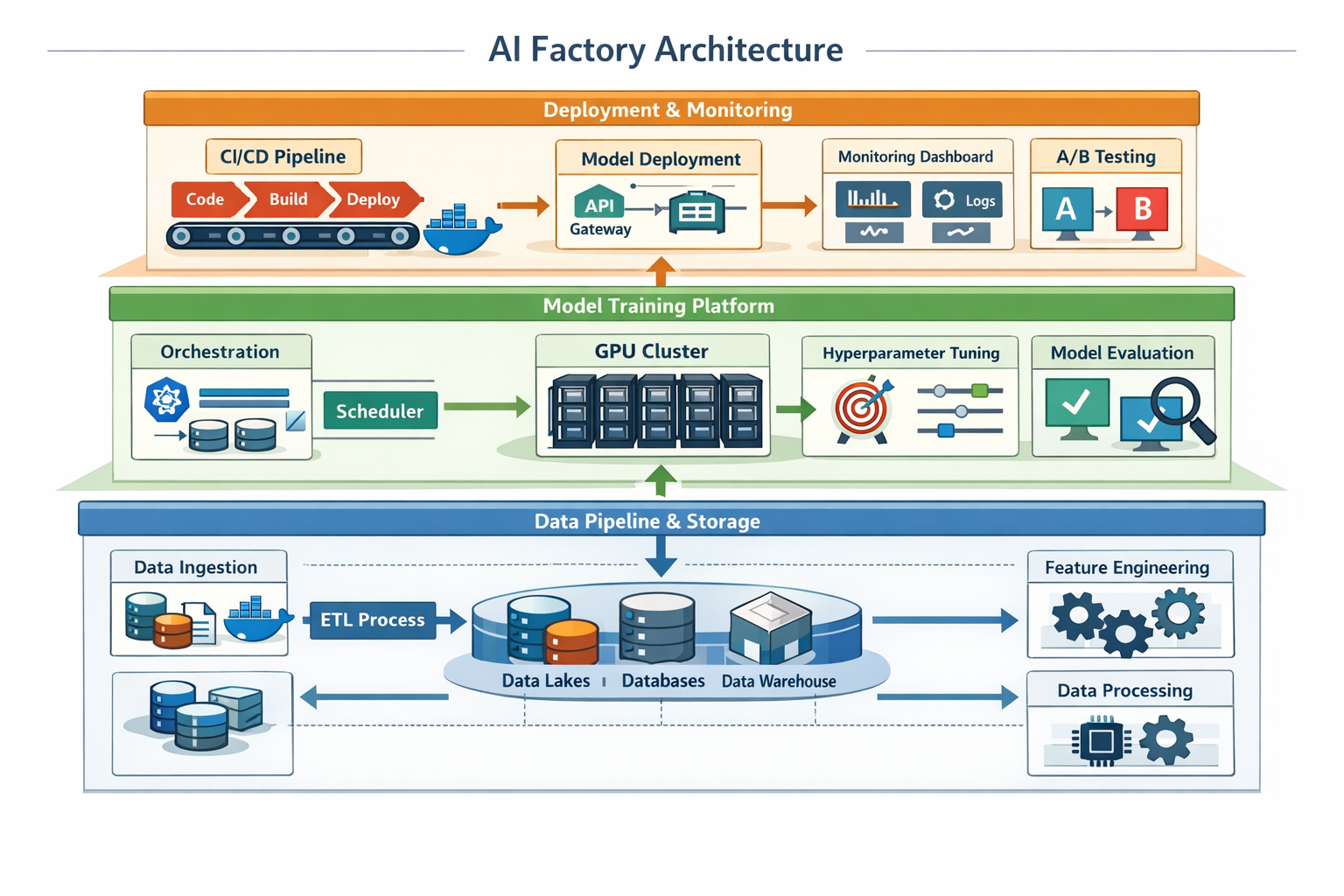
AI factories are integrated enterprise platforms that industrialize artificial intelligence development and deployment through standardized data pipelines, reusable model components, automated orchestration, and streamlined production workflows. Instead of treating each AI project as a custom effort requiring months of infrastructure setup, AI factories provide ready-to-use building blocks that data science teams can assemble rapidly. This approach reduces deployment timelines from 6-12 months to 2-4 weeks while lowering costs and improving model quality through consistent processes and shared learnings across the organization.
What Are AI Factories and Why Do Enterprises Need Them in 2026?
AI factories are production systems that transform how organizations develop, deploy, and maintain artificial intelligence models at scale. They combine infrastructure, platforms, processes, and cultural practices into a unified environment where data scientists and engineers can move from concept to production rapidly and reliably.
Traditional AI development resembles custom manufacturing—each project starts from scratch with unique infrastructure, disconnected data sources, and manual deployment processes. This approach worked when organizations built one or two models per year, but it breaks down when scaling to dozens or hundreds of AI applications.
Core Components of Modern AI Factories
An effective AI factory includes these essential elements:
- Unified data infrastructure that provides clean, accessible data from across the organization without requiring custom integration for each project
- Standardized development platforms with pre-configured environments, common libraries, and shared tooling that eliminate setup friction
- Model registries and versioning systems that track experiments, enable collaboration, and maintain governance over AI assets
- Automated deployment pipelines that move models from development to production with testing, validation, and rollback capabilities
- Monitoring and observability tools that track model performance, data drift, and business impact in real-time
- Orchestration layers that manage compute resources, schedule training jobs, and optimize infrastructure utilization
Why Traditional Approaches Fail at Scale
Organizations attempting to scale AI without factory infrastructure encounter predictable problems. Data scientists spend 60-80% of their time on data preparation and infrastructure tasks instead of model development. Each team builds custom solutions that can't be reused. Models sit in development for months waiting for deployment resources. Production systems lack proper monitoring, leading to silent failures and degraded performance.
The factory model solves these issues by treating AI development as an industrial process with standardized inputs, repeatable workflows, and quality controls at each stage. Just as manufacturing factories enabled mass production of physical goods, AI factories enable mass production of intelligent applications.
How Does AI Factory Infrastructure Differ from Traditional Data Centers?
AI factory infrastructure prioritizes rapid iteration, flexible compute allocation, and automated workflows over the static, capacity-planned approach of traditional data centers. The architecture must support dynamic workloads that spike during training, require specialized accelerators, and demand tight integration between storage, networking, and compute layers.
Traditional data centers were designed for predictable application workloads with known resource requirements. Capacity planning happened annually, infrastructure changes required lengthy approval processes, and applications ran on dedicated servers or virtual machines with fixed allocations.
Key Architectural Differences
AI factories require fundamentally different infrastructure approaches:
Dynamic resource allocation: Training jobs may need 8-64 GPUs for hours or days, then release those resources completely. The infrastructure must support elastic scaling without manual intervention or lengthy provisioning cycles.
Specialized accelerators: While traditional workloads run on CPUs, AI factories require GPUs, TPUs, or custom AI chips. These accelerators cost significantly more and require different cooling, power, and networking considerations.
High-bandwidth networking: Model training involves moving massive datasets between storage and compute, then synchronizing gradients across multiple accelerators. Network bandwidth becomes a critical bottleneck that doesn't exist in most traditional applications.
Software-defined everything: AI factories rely on container orchestration (Kubernetes), infrastructure-as-code, and automated provisioning. Manual server configuration doesn't scale when data scientists need to spin up new environments multiple times per day.
Integrated data pipelines: Unlike traditional applications that query databases, AI workloads process entire datasets through multi-stage pipelines. Storage systems must support both high-throughput sequential access and random access patterns simultaneously.
Choose On-Premises If You Have These Requirements
Build your AI factory on-premises when you need:
- Data sovereignty compliance that prohibits moving sensitive data to cloud providers
- Sustained high utilization where owning infrastructure costs less than renting (typically above 60-70% utilization)
- Specialized hardware not available from cloud providers or requiring custom configurations
- Predictable long-term workloads that justify capital investment in owned infrastructure
Choose Cloud-Based Infrastructure If You Need
Leverage cloud providers when your situation includes:
- Variable workloads with significant peaks and valleys in compute demand
- Rapid experimentation where teams need access to new hardware or services quickly
- Limited capital budget but operational budget available for consumption-based pricing
- Geographic distribution requiring infrastructure in multiple regions without building data centers
- Avoiding infrastructure management to focus engineering resources on AI development rather than operations
Many successful AI factories use hybrid approaches—maintaining on-premises infrastructure for baseline workloads and sensitive data while bursting to cloud for peak demands and experimentation.
What Are the Five Essential Building Blocks for AI Factories Unleashed: Building Enterprise Infrastructure for Rapid Model Deployment in 2026?
The foundation of any successful AI factory rests on five interconnected building blocks: data infrastructure, development platforms, orchestration systems, deployment automation, and observability tools. Each component must work seamlessly with the others to create an environment where data scientists can focus on solving business problems rather than wrestling with infrastructure.
Building Block 1: Data Infrastructure and Pipelines
Data infrastructure provides the raw material for AI factories. Without clean, accessible, well-organized data, even the most sophisticated platforms fail to deliver value.
Key components include:
- Data lakes or lakehouses that store raw data in cost-effective object storage while providing query capabilities
- Feature stores that centralize engineered features, enable reuse across projects, and maintain consistency between training and production
- Data catalogs that help teams discover available datasets, understand lineage, and assess quality
- ETL/ELT pipelines that automate data movement, transformation, and validation
- Data quality monitoring that detects issues before they corrupt model training
Organizations should start by identifying their most valuable data sources and building reliable pipelines to make that data available in standardized formats. Attempting to integrate every data source simultaneously leads to analysis paralysis and delayed value delivery.
Building Block 2: Model Development Platforms
Development platforms provide consistent environments where data scientists can experiment, collaborate, and iterate rapidly without infrastructure friction.
Essential platform capabilities:
- Managed notebooks (JupyterLab, VS Code) with pre-configured libraries and access to data
- Experiment tracking that logs parameters, metrics, and artifacts for every training run
- Model registries that version models, track lineage, and manage the transition from development to production
- Collaborative workspaces where teams can share code, review experiments, and build on each other's work
- Compute flexibility allowing data scientists to request appropriate resources (CPU, GPU, memory) for each task
Platforms like Databricks, SageMaker, or Vertex AI provide these capabilities as managed services, while organizations with specific requirements can assemble open-source components (MLflow, Kubeflow, etc.) into custom platforms.
Building Block 3: Orchestration and Resource Management
Orchestration systems manage the complex workflows that transform data into deployed models while optimizing infrastructure utilization and costs.
Critical orchestration functions:
- Workflow scheduling that chains together data preparation, training, validation, and deployment steps
- Resource allocation that assigns compute resources based on job requirements and priorities
- Queue management that handles multiple concurrent jobs without resource conflicts
- Cost optimization that selects appropriate instance types and shuts down idle resources
- Multi-tenancy that isolates teams and projects while sharing underlying infrastructure
NVIDIA's Run:ai platform exemplifies modern orchestration, providing GPU pooling, fractional GPU allocation, and intelligent scheduling that maximizes utilization. Organizations can also build orchestration layers using Kubernetes operators, Apache Airflow, or Prefect depending on their specific requirements.
Building Block 4: Deployment Automation and CI/CD
Deployment automation bridges the gap between model development and production systems, eliminating the manual handoffs that create bottlenecks and errors.
Key deployment capabilities:
- Containerization that packages models with dependencies for consistent execution across environments
- Automated testing that validates model performance, data compatibility, and integration points before production
- Gradual rollouts that deploy new models to small traffic percentages before full release
- A/B testing frameworks that compare model versions and measure business impact
- Rollback mechanisms that quickly revert to previous versions when issues arise
Organizations should establish clear promotion criteria (accuracy thresholds, latency requirements, business metrics) that models must meet before advancing through development, staging, and production environments. Automated gates enforce these criteria consistently without requiring manual reviews for every deployment.
Building Block 5: Monitoring and Observability
Monitoring systems provide visibility into model behavior, data quality, and business impact after deployment, enabling teams to detect and resolve issues before they affect customers or operations.
Essential monitoring capabilities:
- Performance tracking that measures prediction latency, throughput, and error rates
- Data drift detection that identifies when input distributions change from training data
- Model drift monitoring that catches degrading accuracy or changing prediction patterns
- Business metric tracking that connects model predictions to revenue, costs, or other outcomes
- Alerting and incident response that notifies teams when thresholds are exceeded
Effective monitoring requires instrumenting both the model serving infrastructure and the business processes that consume predictions. Organizations often discover that their most critical models lack basic observability, making it impossible to diagnose issues or measure value delivery.
How Can Organizations Build AI Factories Without Massive GPU Investments?
Organizations can establish effective AI factories by optimizing software infrastructure, leveraging cloud resources strategically, and focusing on smaller models that deliver business value without requiring cutting-edge hardware. The hyperscaler approach of spending billions on GPU clusters represents one path, but most enterprises can achieve significant AI capabilities with more modest investments.
Start with Software-Defined Infrastructure
The most impactful investments often involve software platforms and processes rather than hardware. Organizations that standardize development environments, automate deployment pipelines, and implement proper monitoring see dramatic improvements in AI productivity regardless of their compute resources.
High-impact software investments include:
- Container orchestration platforms (Kubernetes) that maximize utilization of existing hardware
- Model optimization tools that reduce inference costs through quantization, pruning, and distillation
- Efficient training frameworks that minimize GPU hours required for model development
- Resource scheduling systems that ensure expensive accelerators stay busy with productive work
- Development platforms that eliminate setup friction and enable data scientists to focus on modeling
A well-optimized software stack can deliver 3-5x better utilization of existing hardware compared to ad-hoc infrastructure, effectively multiplying compute capacity without purchasing additional servers.
Leverage Cloud for Peak Demands and Experimentation
Cloud providers offer access to the latest accelerators without capital investment, making them ideal for experimentation, proof-of-concepts, and handling peak workloads that exceed on-premises capacity.
Strategic cloud usage patterns:
- Rent expensive GPUs (A100, H100) for short-duration training jobs rather than purchasing them for occasional use
- Use spot instances for fault-tolerant workloads, achieving 60-80% cost savings compared to on-demand pricing
- Leverage managed services for capabilities that would require significant engineering effort to build internally
- Experiment with new architectures before committing to hardware purchases
- Scale geographically without building data centers in multiple regions
Organizations should calculate the utilization threshold where owning infrastructure becomes more cost-effective than renting. For most enterprises, this occurs around 60-70% sustained utilization, though the exact breakpoint depends on specific hardware costs and cloud pricing.
Focus on Smaller, Optimized Models
The AI industry's focus on ever-larger models obscures the reality that many business problems can be solved effectively with smaller models that run on modest hardware.
Strategies for efficient model development:
- Start with smaller architectures and only scale up if business requirements demand it
- Use transfer learning to leverage pre-trained models rather than training from scratch
- Apply model compression techniques (quantization, pruning, knowledge distillation) to reduce resource requirements
- Optimize for inference efficiency since most costs come from serving predictions rather than training
- Choose appropriate model types for each problem rather than defaulting to the largest available foundation model
A well-optimized smaller model often delivers better business value than a massive model that's too expensive to deploy widely or too slow to meet latency requirements. Organizations should define success criteria based on business outcomes rather than model size or benchmark performance.
Build Incrementally Based on Demonstrated Value
Rather than attempting to build complete AI factory infrastructure upfront, successful organizations start with minimal viable platforms and expand based on demonstrated value and identified bottlenecks.
Incremental build approach:
- Start with a single high-value use case that justifies initial platform investment
- Build minimal infrastructure required to deliver that use case to production
- Measure business impact and identify the biggest friction points in the development process
- Invest in removing bottlenecks that prevent scaling to additional use cases
- Expand gradually as the portfolio of AI applications grows and justifies additional infrastructure
This approach avoids the common mistake of building elaborate infrastructure that sits unused because the organization lacks the AI maturity to leverage it effectively. Infrastructure should follow demonstrated demand rather than preceding it.
What Are the Common Pitfalls When Implementing AI Factories Unleashed: Building Enterprise Infrastructure for Rapid Model Deployment in 2026?
The majority of AI factory initiatives fail not due to technical limitations but because organizations underestimate organizational change, rush deployment without solid foundations, or optimize for the wrong metrics. Understanding these common pitfalls helps organizations avoid expensive mistakes and build sustainable AI capabilities.
Pitfall 1: Technology-First Approach Without Organizational Readiness
Organizations frequently purchase sophisticated AI platforms before establishing the processes, skills, and culture required to use them effectively. The result is expensive infrastructure that sits underutilized while teams continue working in their familiar ad-hoc patterns.
Warning signs of this pitfall:
- Purchasing enterprise AI platforms before defining clear use cases or success metrics
- Expecting tools alone to transform AI capabilities without process changes
- Lacking data scientists or ML engineers who can leverage advanced platform features
- Missing executive sponsorship for the organizational changes required to adopt new workflows
- Underestimating the change management effort required to shift from project-based to platform-based development
How to avoid it: Start with pilot projects that demonstrate value and build organizational muscle before scaling infrastructure. Invest in training, process definition, and change management alongside technology purchases. Ensure teams understand why new approaches benefit them rather than imposing top-down mandates.
Pitfall 2: Rushing Deployment Without Solid Foundations
The pressure to show rapid AI results leads organizations to skip foundational work on data quality, infrastructure automation, and operational processes. These shortcuts create technical debt that eventually prevents scaling and requires expensive rework.
As RackN CEO Rob Hirschfeld noted in January 2026, organizations must resist the temptation to rush deployments without establishing solid foundations and repeatable processes. Power restrictions, bare metal automation needs, and infrastructure complexity demand careful planning rather than hasty implementation.
Critical foundation elements often skipped:
- Data governance and quality processes that ensure models train on reliable information
- Infrastructure-as-code practices that make environments reproducible and auditable
- Security and compliance controls built into platforms from the start rather than added later
- Monitoring and observability that provide visibility into system behavior and model performance
- Documentation and knowledge sharing that enable teams to learn from each other's experiences
How to avoid it: Define minimum standards for data quality, infrastructure automation, and operational practices before deploying production models. Accept slower initial progress in exchange for sustainable long-term scaling. Treat the first few projects as opportunities to establish patterns rather than racing to production.
Pitfall 3: Optimizing for Model Accuracy Instead of Business Value
Data science teams naturally focus on improving model accuracy, but many organizations discover that their most accurate models deliver minimal business value because they're too slow, too expensive, or solve the wrong problems.
Symptoms of misaligned optimization:
- Models that achieve impressive benchmark scores but can't meet production latency requirements
- Pursuing marginal accuracy improvements that don't translate to better business outcomes
- Building sophisticated models for problems where simple rules or heuristics would suffice
- Measuring success by number of models deployed rather than business impact delivered
- Lacking clear connections between model predictions and revenue, costs, or customer satisfaction
How to avoid it: Define business success criteria before starting model development. Establish acceptable tradeoffs between accuracy, latency, cost, and interpretability based on actual business requirements. Measure model value through business metrics rather than technical metrics. Be willing to deploy simpler models that deliver 80% of the value at 20% of the cost.
Pitfall 4: Neglecting the Production Environment
Organizations invest heavily in development platforms while treating production deployment as an afterthought. This creates a gap where models work perfectly in development but fail or underperform in production due to different data, infrastructure, or integration requirements.
Common production environment gaps:
- Development environments that don't match production infrastructure or data characteristics
- Missing monitoring and alerting for deployed models
- Lack of automated rollback mechanisms when models fail
- No processes for handling data drift or model degradation
- Insufficient load testing before deploying to production traffic
- Missing integration with existing business systems and workflows
How to avoid it: Design production requirements into the AI factory from the beginning. Ensure development environments mirror production as closely as possible. Implement comprehensive monitoring and incident response processes. Test models under realistic production conditions before full deployment. Treat model deployment as the beginning of the lifecycle rather than the end.
Pitfall 5: Ignoring Power and Infrastructure Constraints
The explosive growth in AI workloads has created power and cooling constraints that many organizations underestimate when planning AI factories. Global data center electricity consumption is projected to double between 2022 and 2026, with AI workloads driving much of this growth.
Microsoft's $80 billion Azure order backlog remains unfulfilled primarily due to power constraints rather than hardware availability. Organizations planning significant AI infrastructure must address power, cooling, and physical space requirements early in the design process.
Infrastructure constraints to address:
- Power availability in existing data centers or cloud regions
- Cooling capacity for high-density GPU clusters that generate significant heat
- Network bandwidth between storage, compute, and serving infrastructure
- Physical space for additional racks and cooling equipment
- Permitting and compliance for new data center construction or major expansions
How to avoid it: Conduct infrastructure assessments before committing to large-scale AI deployments. Work with facilities teams to understand power and cooling constraints. Consider distributed architectures that spread workloads across multiple locations. Plan for infrastructure lead times that may extend 12-24 months for significant expansions.
How Do Leading Organizations Approach AI Factory Implementation?
Successful AI factory implementations share common patterns: starting with clear business objectives, building incrementally, establishing strong governance, and treating AI as a product rather than a project. Examining these approaches provides practical guidance for organizations beginning their AI factory journey.
The Platform Team Model
Leading organizations establish dedicated platform teams responsible for building and maintaining AI factory infrastructure, separate from the data science teams that use the platform to deliver business value.
Platform team responsibilities:
- Infrastructure management: Provisioning, configuring, and maintaining compute, storage, and networking resources
- Tool selection and integration: Evaluating, deploying, and supporting development tools and frameworks
- Self-service enablement: Creating documentation, templates, and automation that allow data science teams to work independently
- Performance optimization: Monitoring utilization, identifying bottlenecks, and improving efficiency
- Security and compliance: Implementing controls, conducting audits, and ensuring regulatory requirements are met
This separation of concerns allows data scientists to focus on model development while platform engineers focus on infrastructure reliability and efficiency. The platform team treats data science teams as internal customers, measuring success through adoption, satisfaction, and productivity improvements.
The Product-Oriented Approach
Rather than treating AI models as one-off projects, successful organizations manage them as products with ongoing development, maintenance, and improvement cycles.
Product-oriented practices:
- Assigning product owners who define requirements, prioritize features, and measure business impact
- Maintaining model roadmaps that plan improvements, updates, and new capabilities
- Allocating ongoing resources for monitoring, retraining, and enhancement rather than moving teams to new projects after initial deployment
- Measuring product metrics like user adoption, business value delivered, and customer satisfaction
- Iterating based on feedback from users and business stakeholders
This approach prevents the common pattern where models degrade over time because no one is responsible for maintaining them after the initial development team moves on. Similar to how mortgage brokers provide ongoing service rather than one-time transactions, AI products require continuous attention to deliver sustained value.
The Center of Excellence Pattern
Many organizations establish AI Centers of Excellence that combine platform development, best practice sharing, and hands-on support for business units implementing AI solutions.
Center of Excellence functions:
- Platform development and operation as described in the platform team model
- Standards and best practices that ensure consistency and quality across the organization
- Training and enablement that builds AI capabilities throughout the organization
- Project consulting where CoE members join business unit teams for critical initiatives
- Innovation and research exploring new techniques and technologies before broad adoption
The CoE model works well for large organizations where multiple business units need AI capabilities but lack the scale to justify dedicated platform teams. The CoE provides shared infrastructure and expertise while allowing business units to maintain ownership of their specific use cases and models.
The Federated Approach
Some organizations adopt federated models where business units maintain significant autonomy while adhering to enterprise standards and leveraging shared infrastructure.
Federated model characteristics:
- Business unit ownership of AI strategy, use cases, and implementation
- Enterprise platform providing shared infrastructure and services
- Common standards for security, governance, and key technical decisions
- Shared services like data platforms, model registries, and monitoring tools
- Community of practice where teams share learnings and collaborate on common challenges
This approach balances the need for enterprise-wide consistency with the reality that different business units have unique requirements and move at different speeds. It works best in organizations with strong business unit autonomy and mature engineering practices.
What Role Do Hyperscalers Play in Enterprise AI Factory Strategies?
Hyperscalers like Microsoft, Google, Amazon, and Meta are investing unprecedented amounts in AI infrastructure—projected at $660-690 billion in 2026—but enterprises can leverage these investments without matching their spending through strategic use of cloud services and managed platforms. Understanding hyperscaler strategies helps organizations make informed decisions about their own infrastructure approaches.
Hyperscaler Investment Trends
The scale of hyperscaler AI infrastructure investment is staggering and accelerating. Microsoft targets over $120 billion in capital expenditure for fiscal 2026, while Meta plans $115-135 billion for the same period. These investments focus on AI compute, data centers, networking, and power infrastructure.
These massive investments reflect several realities:
- AI workloads are growing faster than efficiency improvements, requiring continuous capacity expansion
- Competition for AI leadership drives aggressive infrastructure buildouts to support both internal products and cloud services
- Power and physical infrastructure constraints require long lead times and massive capital commitments
- First-mover advantages in AI capabilities justify front-loading infrastructure investment
For enterprises, these investments create both opportunities and challenges. Cloud services provide access to cutting-edge infrastructure without capital investment, but dependence on hyperscalers raises questions about costs, vendor lock-in, and strategic control.
Leveraging Hyperscaler Platforms Without Full Dependence
Smart enterprises use hyperscaler platforms strategically while maintaining flexibility and avoiding complete dependence on any single provider.
Balanced hyperscaler strategies:
- Use managed services for undifferentiated capabilities (data storage, basic compute, networking) where building internally provides no competitive advantage
- Maintain portability for core AI workloads through containerization and open standards that enable multi-cloud or hybrid deployment
- Leverage specialized services (like NVIDIA's AI Factory building blocks available through cloud providers) for capabilities that would be expensive to build internally
- Negotiate enterprise agreements that provide cost predictability and volume discounts for sustained usage
- Maintain on-premises options for sensitive workloads, compliance requirements, or sustained high-utilization scenarios where ownership is more economical
Organizations should view hyperscalers as infrastructure providers rather than strategic partners, maintaining the ability to shift workloads between providers or bring them on-premises if business conditions change.
Regional Considerations and Data Sovereignty
The global distribution of hyperscaler infrastructure creates opportunities and constraints for enterprises operating in different regions. Europe has established 13 AI factories across 17 member states, with European AI server spending forecasted at $47 billion in 2026, reflecting both regional AI ambitions and data sovereignty requirements.
Regional infrastructure factors:
- Data residency requirements that mandate certain data remain within specific geographic boundaries
- Latency considerations for applications requiring low-latency access to AI models
- Cost variations between regions based on power costs, real estate, and local market conditions
- Service availability as not all hyperscaler services are available in all regions
- Regulatory compliance with regional requirements for data protection, AI governance, and industry-specific regulations
Organizations with international operations must design AI factory architectures that accommodate these regional variations while maintaining consistency in development practices and operational processes. Just as mortgage regulations vary by region, AI infrastructure must adapt to local requirements while maintaining global standards.
How Should Organizations Measure AI Factory Success?
Effective AI factory measurement combines technical metrics (deployment velocity, infrastructure utilization), business metrics (value delivered, cost savings), and organizational metrics (team productivity, capability growth) into a balanced scorecard that tracks progress toward strategic objectives. Organizations that optimize for single metrics often achieve hollow victories that don't translate to business success.
Technical Performance Metrics
Technical metrics measure how well the AI factory infrastructure and processes function, providing early indicators of problems and opportunities for optimization.
Key technical metrics:
- Time to production: Days or weeks from project start to deployed model serving production traffic
- Deployment frequency: Number of model updates deployed per week or month
- Infrastructure utilization: Percentage of compute resources actively performing useful work
- Model training efficiency: GPU hours or cost required to train models to target accuracy
- Inference latency: Time required to generate predictions for production requests
- System reliability: Uptime, error rates, and incident frequency for production models
Organizations should establish baselines for these metrics early and track improvements over time. A well-functioning AI factory should show steady improvements in deployment velocity and infrastructure efficiency as processes mature and automation increases.
Business Value Metrics
Business metrics connect AI factory activities to organizational objectives, ensuring technical progress translates to real value.
Critical business metrics:
- Revenue impact: Incremental revenue generated by AI-powered features or products
- Cost savings: Operational costs reduced through automation or optimization
- Customer satisfaction: Improvements in NPS, retention, or satisfaction scores attributable to AI capabilities
- Process efficiency: Time or resources saved in business processes enhanced by AI
- Risk reduction: Fraud prevented, compliance violations avoided, or other risk mitigation
- Return on investment: Total value delivered compared to AI factory costs
Organizations should establish clear attribution models that connect model predictions to business outcomes. This often requires instrumenting business processes to track how AI recommendations influence decisions and results. Without clear business value measurement, AI factories risk becoming expensive science projects that don't justify their costs.
Organizational Capability Metrics
Organizational metrics track the growth of AI capabilities and culture across the enterprise, measuring progress toward strategic AI maturity.
Important capability metrics:
- Team productivity: Models deployed per data scientist or engineer
- Skill development: Number of employees trained in AI techniques and tools
- Reuse and collaboration: Percentage of projects leveraging shared components or features
- Cross-functional engagement: Business units actively using AI factory capabilities
- Innovation rate: New use cases or applications identified and developed
- Knowledge sharing: Documentation created, best practices established, and learnings disseminated
These metrics indicate whether the AI factory is building sustainable organizational capabilities or simply delivering one-off projects. Successful AI factories show increasing productivity, broader adoption across business units, and growing internal expertise over time.
Balanced Scorecard Approach
Rather than optimizing for any single metric, leading organizations use balanced scorecards that track progress across technical, business, and organizational dimensions simultaneously.
Scorecard design principles:
- Include leading and lagging indicators: Technical metrics often lead business results, providing early signals of success or problems
- Balance efficiency and innovation: Pure efficiency optimization can stifle experimentation and learning
- Measure both outputs and outcomes: Track models deployed (output) and business value delivered (outcome)
- Adjust metrics as maturity grows: Early-stage AI factories focus on deployment velocity; mature factories optimize for business impact
- Review regularly with stakeholders: Monthly or quarterly reviews ensure metrics remain aligned with strategic objectives
Organizations should resist the temptation to create elaborate measurement frameworks with dozens of metrics. A focused set of 10-15 key metrics provides sufficient visibility without creating measurement overhead that consumes more time than it provides value.
What Are the Security and Governance Considerations for AI Factories?
AI factories introduce unique security and governance challenges including model theft, data poisoning, adversarial attacks, and regulatory compliance requirements that traditional IT security frameworks don't fully address. Organizations must extend their security and governance practices to cover the entire AI lifecycle from data collection through model deployment and monitoring.
Data Security and Privacy
AI models require access to large volumes of data, often including sensitive customer information, proprietary business data, or regulated content. Protecting this data throughout the AI lifecycle requires comprehensive controls.
Essential data security practices:
- Data classification and access controls that restrict access based on sensitivity and need-to-know principles
- Encryption at rest and in transit for all data used in model training and inference
- Data minimization that limits collection and retention to what's necessary for specific purposes
- Privacy-preserving techniques like differential privacy, federated learning, or synthetic data generation when appropriate
- Audit logging that tracks data access, usage, and transformations throughout the AI pipeline
- Secure data deletion when data reaches retention limits or individuals exercise privacy rights
Organizations must balance data access for AI development with privacy and security requirements. Overly restrictive controls prevent data scientists from accessing the data they need, while insufficient controls create compliance risks and potential breaches.
Model Security and Intellectual Property Protection
AI models themselves represent valuable intellectual property that requires protection from theft, reverse engineering, or unauthorized use.
Model protection strategies:
- Access controls that restrict who can view model architectures, parameters, or training data
- Model encryption for stored models and during transmission
- Secure serving environments that prevent model extraction through API abuse
- Watermarking and fingerprinting that enable detection of stolen or unauthorized model copies
- Rate limiting and monitoring to detect and prevent model extraction attempts
- Contractual protections for models shared with partners or customers
Organizations should assess the value and sensitivity of their models to determine appropriate protection levels. Commodity models using public data require less protection than proprietary models trained on unique datasets that provide competitive advantages.
Adversarial Attack Protection
AI models face unique attack vectors where malicious actors manipulate inputs to cause incorrect predictions or extract sensitive information.
Common adversarial threats:
- Evasion attacks that craft inputs designed to fool models into incorrect predictions
- Poisoning attacks that inject malicious data into training sets to corrupt model behavior
- Model inversion that extracts training data by analyzing model outputs
- Membership inference that determines whether specific data was used in model training
- Backdoor attacks that embed hidden triggers causing models to misbehave under specific conditions
Defense strategies:
- Input validation and sanitization that detects and rejects suspicious inputs
- Adversarial training that exposes models to attack examples during development
- Ensemble methods that combine multiple models to increase attack difficulty
- Monitoring and anomaly detection that identifies unusual prediction patterns
- Regular security testing including red team exercises focused on AI-specific attacks
Organizations deploying AI in security-critical or adversarial environments (fraud detection, content moderation, etc.) should prioritize adversarial robustness alongside traditional accuracy metrics.
Regulatory Compliance and AI Governance
The regulatory landscape for AI is evolving rapidly, with new requirements for transparency, fairness, accountability, and human oversight emerging in multiple jurisdictions.
Key governance requirements:
- Model documentation that records training data, algorithms, performance metrics, and limitations
- Bias testing and mitigation that ensures models don't discriminate against protected groups
- Explainability and transparency that enables understanding of how models make decisions
- Human oversight and intervention for high-stakes decisions affecting individuals
- Impact assessments that evaluate potential harms before deploying models
- Audit trails that enable reconstruction of model decisions and accountability for outcomes
Organizations should establish AI governance frameworks that define roles, responsibilities, and processes for ensuring compliant AI development and deployment. This includes governance boards that review high-risk models, ethics guidelines that inform development decisions, and compliance processes that verify regulatory requirements are met.
Similar to how mortgage lending requires careful documentation and compliance, AI factories must maintain rigorous governance to manage risks and meet regulatory obligations.
What Does the Future Hold for AI Factories in 2026 and Beyond?
The AI factory landscape in 2026 is characterized by increasing standardization, growing emphasis on efficiency over scale, and the emergence of specialized infrastructure for different AI workload types. Organizations that adapt to these trends position themselves for sustained competitive advantage, while those clinging to outdated approaches risk falling behind.
The Shift from Scale to Efficiency
After years of pursuing ever-larger models and infrastructure, the industry is shifting focus toward efficiency, optimization, and doing more with less. This trend is driven by power constraints, cost pressures, and the realization that many business problems don't require frontier models.
Efficiency-focused trends:
- Smaller, specialized models optimized for specific tasks rather than general-purpose foundation models
- Model compression techniques becoming standard practice rather than advanced optimization
- Inference optimization receiving as much attention as training efficiency
- Energy efficiency becoming a key metric alongside performance and accuracy
- Cost-conscious architecture that balances capability with operational expenses
Organizations should resist the temptation to always use the largest available models, instead matching model complexity to business requirements and available infrastructure.
Standardization and Interoperability
The AI infrastructure landscape is consolidating around common standards, frameworks, and interfaces that reduce vendor lock-in and enable portability.
Standardization developments:
- Container-based deployment becoming universal for model serving
- Common model formats (ONNX, TensorFlow SavedModel) enabling cross-framework compatibility
- Standardized APIs for model serving, monitoring, and management
- Open-source platforms providing alternatives to proprietary vendor solutions
- Industry consortiums developing best practices and reference architectures
This standardization benefits enterprises by reducing switching costs, enabling multi-vendor strategies, and allowing organizations to leverage best-of-breed components rather than accepting complete vendor stacks.
Specialized Infrastructure for Different Workload Types
Rather than building monolithic AI factories, organizations are creating specialized infrastructure optimized for different workload characteristics.
Workload-specific infrastructure patterns:
- Training clusters with high-bandwidth networking and specialized accelerators for large-scale model development
- Inference infrastructure optimized for low latency, high throughput, and cost efficiency
- Edge deployment for applications requiring local processing or operating in disconnected environments
- Batch processing systems for non-real-time workloads that can tolerate higher latency
- Hybrid architectures that combine on-premises, cloud, and edge resources based on workload requirements
Organizations should design infrastructure that matches their specific workload mix rather than assuming a single architecture serves all needs. This specialization improves both performance and cost efficiency compared to one-size-fits-all approaches.
The Rise of AI Operations (AIOps)
As AI deployments scale, organizations are developing specialized operational practices and tools for managing AI systems in production, creating a new discipline analogous to DevOps for traditional software.
AIOps practices and tools:
- Automated model monitoring that detects performance degradation, data drift, and anomalies
- Continuous training pipelines that automatically retrain models when performance declines
- Feature store management that maintains consistency between training and production
- Model versioning and rollback that enables rapid response to production issues
- Performance optimization that continuously tunes models and infrastructure for efficiency
Organizations that invest in AIOps capabilities gain significant advantages in reliability, efficiency, and time-to-value compared to those treating AI operations as an afterthought.
Integration with Business Processes
The most successful AI factories in 2026 are those that tightly integrate AI capabilities with existing business processes and systems rather than treating AI as a separate technology layer.
Integration patterns:
- Embedded AI within business applications rather than standalone AI systems
- Decision support that augments human judgment rather than replacing it entirely
- Workflow integration that incorporates AI predictions into existing business processes
- Feedback loops that capture business outcomes to improve model performance
- Change management that helps organizations adapt processes to leverage AI capabilities
Organizations should design AI solutions with business integration in mind from the start, involving business stakeholders throughout development rather than building models in isolation and attempting integration afterward.
Frequently Asked Questions
What is an AI factory?
An AI factory is an integrated platform that industrializes artificial intelligence development and deployment through standardized infrastructure, automated pipelines, reusable components, and streamlined workflows. It reduces model deployment time from months to weeks by eliminating repetitive setup work and providing ready-to-use building blocks for data science teams.
How much does it cost to build an AI factory?
AI factory costs vary dramatically based on scale and approach. Small organizations can start with $50,000-$200,000 in cloud services and platform software, while large enterprises may invest $5-20 million in on-premises infrastructure. Most costs come from ongoing operational expenses (cloud services, personnel, power) rather than initial capital investment. Start small with pilot projects and scale based on demonstrated value.
Do I need GPUs to build an AI factory?
Not necessarily. Many AI workloads run effectively on CPUs, especially for inference and smaller models. Organizations can leverage cloud GPU resources for training while running inference on less expensive infrastructure. Focus on software platforms, data pipelines, and processes before investing in expensive hardware. GPU requirements depend on your specific use cases and scale.
How long does it take to implement an AI factory?
A minimal viable AI factory can be operational in 2-3 months, providing basic capabilities for a single use case. Building comprehensive enterprise infrastructure typically requires 6-12 months. However, AI factories should evolve continuously based on usage patterns and identified bottlenecks rather than attempting complete implementation before delivering value. Start small and expand incrementally.
What skills do teams need to operate an AI factory?
Core skills include data engineering (building pipelines and managing data infrastructure), ML engineering (deploying and operating models in production), platform engineering (managing Kubernetes, cloud infrastructure, and automation), and data science (developing models). Organizations also need product managers who understand both AI capabilities and business requirements. Consider building these skills gradually through training and strategic hiring.
How do AI factories differ from traditional ML platforms?
AI factories encompass the entire AI lifecycle from data collection through production deployment and monitoring, while traditional ML platforms focus primarily on model development. AI factories emphasize automation, standardization, and integration with business processes. They treat AI as a production capability rather than a research activity, with corresponding emphasis on reliability, efficiency, and business value delivery.
Can small companies benefit from AI factory approaches?
Yes. Small companies can implement AI factory principles using cloud services and open-source tools without massive infrastructure investments. The key benefits—standardized processes, reusable components, automated deployment—apply at any scale. Start with lightweight platforms like managed notebook services, basic CI/CD pipelines, and simple monitoring. The organizational practices matter more than expensive infrastructure.
What are the biggest challenges in AI factory implementation?
Organizational challenges typically exceed technical ones. Common obstacles include resistance to new workflows, lack of executive sponsorship, insufficient data quality, skills gaps, and unclear business objectives. Technical challenges include infrastructure complexity, integration with existing systems, and scaling to production workloads. Address organizational readiness before investing heavily in technology.
How do I measure ROI for an AI factory?
Measure ROI through a combination of efficiency gains (reduced time to deploy models, improved infrastructure utilization, lower development costs) and business value delivered (revenue increases, cost savings, improved customer satisfaction). Track both leading indicators (deployment velocity, team productivity) and lagging indicators (business impact, financial returns). Expect 6-12 months before seeing significant ROI as teams learn new platforms and processes.
Should I build or buy AI factory infrastructure?
Most organizations should buy managed platforms for undifferentiated capabilities (data storage, compute, basic ML tools) and build only specialized components that provide competitive advantages. Cloud providers offer comprehensive AI platforms that eliminate infrastructure management overhead. Build custom infrastructure only when you have specific requirements that commercial platforms don't address or when sustained high utilization makes ownership more economical than renting.
How do AI factories handle data privacy and security?
AI factories implement security controls throughout the AI lifecycle including data encryption, access controls, audit logging, and privacy-preserving techniques. Model security prevents theft or unauthorized use. Governance frameworks ensure compliance with regulations and ethical guidelines. Security should be designed into the platform from the start rather than added later. Treat AI security as an extension of existing information security programs with additional controls for AI-specific risks.
What role does MLOps play in AI factories?
MLOps provides the operational practices and tools that make AI factories function reliably at scale. It encompasses model versioning, automated testing, deployment pipelines, monitoring, and incident response. MLOps to AI factories is what DevOps is to software development—the discipline that bridges development and operations. Organizations with mature MLOps practices deploy models faster, maintain higher reliability, and respond to issues more quickly than those treating operations as an afterthought.
Conclusion
AI Factories Unleashed: Building Enterprise Infrastructure for Rapid Model Deployment in 2026 represents a fundamental transformation in how organizations develop and deploy artificial intelligence capabilities. The shift from project-based AI development to industrialized production systems enables enterprises to deliver models to production in weeks instead of months, scale AI across their organizations, and achieve meaningful business value from their AI investments.
Success requires balancing technical infrastructure with organizational readiness, starting small and scaling based on demonstrated value, and maintaining focus on business outcomes rather than technical sophistication. Organizations that build solid foundations—clean data pipelines, automated deployment processes, comprehensive monitoring, and strong governance—position themselves for sustainable AI capabilities that compound over time.
The hyperscaler investments of $660-690 billion in 2026 demonstrate the strategic importance of AI infrastructure, but enterprises don't need to match these investments to benefit from AI factory approaches. Strategic use of cloud services, focus on software-defined platforms, and emphasis on smaller optimized models enable organizations of any size to build effective AI capabilities.
Actionable Next Steps
Organizations beginning their AI factory journey should take these concrete actions:
Immediate actions (next 30 days):
- Identify a high-value pilot use case that justifies initial platform investment and has clear success metrics
- Assess current infrastructure and capabilities to understand gaps between current state and AI factory requirements
- Establish executive sponsorship with clear understanding of required investments and expected timelines
- Form a cross-functional team including data science, engineering, business stakeholders, and operations
Short-term actions (3-6 months):
- Deploy minimal viable platform with basic development environment, data access, and deployment automation for the pilot use case
- Establish foundational practices including version control, experiment tracking, and basic monitoring
- Deliver pilot to production and measure both technical performance and business impact
- Document learnings and identify bottlenecks that would prevent scaling to additional use cases
- Begin training programs to build AI capabilities across the organization
Medium-term actions (6-12 months):
- Expand platform capabilities based on identified bottlenecks and requirements from additional use cases
- Scale to 3-5 production models across different business units to validate platform generalizability
- Implement comprehensive governance including security controls, compliance processes, and ethical guidelines
- Establish AIOps practices for monitoring, incident response, and continuous improvement
- Measure and communicate ROI to justify continued investment and expansion
Long-term strategic actions (12+ months):
- Build specialized infrastructure optimized for different workload types based on usage patterns
- Develop internal AI expertise through training, hiring, and knowledge sharing programs
- Integrate AI capabilities deeply into business processes and decision-making
- Continuously optimize for efficiency, cost, and business value as the platform matures
- Stay current with evolving best practices and technologies in the rapidly changing AI landscape
The journey to effective AI factories requires patience, persistence, and willingness to learn from both successes and failures. Organizations that commit to this journey position themselves for sustained competitive advantage in an increasingly AI-driven business environment. The question is no longer whether to build AI capabilities, but how quickly and effectively organizations can industrialize AI development to capture the opportunities ahead.
SEO Meta Title and Description
Meta Title: AI Factories 2026: Enterprise Infrastructure for Rapid Deployment
Meta Description: Build enterprise AI factories for rapid model deployment in 2026. Step-by-step blueprints, case studies, and strategies to accelerate AI without massive GPU investments.